 DTM tutorial
DTM tutorialTheory
With the rapid development of business and increasing business complexity, almost every company's system will move from the monolithic architecture to a distributed, especially microservice-based one. Naturally with this change comes the challenging difficulty of distributed transactions. Our DTM is committed to providing an easy-to-use, language-agnostic, high-performance and scalable distributed transaction solution.
Basic Theory
Before explaining the our DTM solution, let's review some basic theoretical knowledge necessary for distributed transactions.
Let's take a money transfer as an example: A wants to transfer $100 to B. What needs to be done is thus to subtract $100 from A's balance and to add $100 to B's balance. The guarantee must be provided that the entire transfer, namely A-$100 and B+$100, either succeeds or fails atomically as a whole. Let's see how this problem is solved in various scenarios.
Transactions
The functionality to execute multiple statements as a whole is known as a database transaction. A database transaction ensures that all operations within the scope of that transaction either all succeed or all fail.
Transactions have four properties: atomicity, consistency, isolation, and persistence. These four properties are commonly referred to as ACID characteristics.
Atomicity: All operations in a transaction either complete or do not complete, but never end at some point in the middle. A transaction that meets an error during execution is rolled back so that the system is restored to the state it was in before the transaction began, as if the transaction had never been executed.
Consistency: The integrity of the database is not broken before the transaction starts and after the transaction ends. Integrity including foreign key constraints, application-defined constraints, etc, will not be broken.
Isolation: The database allows multiple concurrent transactions to read, write and modify its data at the same time. Isolation prevents data inconsistencies due to cross-execution when multiple transactions are executed concurrently.
Persistence: After the transaction is finished, the modification of the data is permanent and will not be lost even if the system fails.
Distributed theory
A distributed system can only satisfy at most two of the three criteria of Consistency, Availability, and Partition tolerance at the same time. This is called CAP theory and has been proven.
C Consistency
In distributed systems, data is usually stored in copies on different nodes. If an update operation has been successfully executed on the data on the first node, but the data on the second node is not yet updated accordingly, then the data read from the second node will be the data before the update, i.e., dirty data, which is the case of data inconsistency in distributed systems.
In a distributed system, if it is possible to achieve that all users can read the latest value after a successful execution of an update operation on a data item, then the system is considered to have strong consistency (or strict consistency).
Please note that the consistency in CAP and the consistency in ACID, although with the same wording, have different meanings in practice. Please pay attention to the differences.
A Availability
Availability means whether the cluster as a whole can still respond to client read and write requests after a failure of some of the nodes in the cluster. (High availability for data updates)
In modern Internet applications, it is unacceptable if the service is unavailable for a long time due to problems such as server downtime.
P Partitioning tolerance
In practical terms, partitioning is equivalent to a time limit on communication. If a system cannot achieve data consistency within the time limit, partitioning occurs and a choice must be made between Consistency and Availability concerning the current operation.
A way to improve partitioning tolerance is to duplicate a data item to multiple nodes, then after partitioning occurs, this data item can still be read in other partitions and tolerance is improved. However, duplicating data to multiple nodes introduces consistency issues, in that the data on different nodes may be inconsistent.
Problems faced
For most scenarios of large Internet applications, there are many hosts deployed in a decentralized fashion. Clusters are now getting larger and larger, so node failures and network failures are normal. The importance to ensure service availability up to N nines means that P and A have higher priorities over C.
If you want to study CAP-related theories in depth, it is recommended to study the raft protocol (PS: Here is a recommended animation to explain the raft protocol: raft animation). Through learning raft, you will be able to understand better the problems faced in distributed systems and the typical solutions.
BASE theory
BASE is a shorthand for the three phrases Basically Available, Soft state, and Eventually consistent. BASE results from a trade-off between consistency and availability in CAP, and is based on the conclusions of distributed practice for large-scale Internet systems and derived from the CAP theory. The core idea is that even though strong consistency cannot be achieved, each application can adopt an appropriate approach, according to its business characteristics, to make the system achieve Eventual consistency. Next, we will focus on the three elements of BASE in detail.
Basic availability means that a distributed system is allowed to lose partial availability in the event of an unpredictable failure - but note that this is in no way equivalent to the system being unavailable.
Weak state, also known as soft state, as opposed to hard state, is the principle of allowing an intermediate state of data in the system and assuming that the existence of that intermediate state does not affect the overall availability of the system, i.e., allowing the system to have a delay in synchronizing data between copies of data on different nodes.
Final consistency emphasizes that all data copies in the distributed system, after a period of synchronization, can eventually reach a consistent state. Therefore, the essence of final consistency is that the system needs to ensure that the final data can reach a consistent state, rather than the strong consistency of the system data in real time.
In summary, BASE theory aims at large, highly available and scalable distributed systems, and is the opposite of the traditional ACID feature of transactions. It is completely different from the strong consistency model of ACID, but proposes to obtain availability by sacrificing strong consistency, and allows data to be inconsistent for a period of time, but eventually reach a consistent state. Nevertheless, in practical distributed scenarios, different business units and components have different requirements for data consistency, so the ACID feature and BASE theory are often used together in the design process of specific distributed system architectures.
Distributed Transactions
The bank interbank transfer business is a typical distributed transaction scenario. Suppose A needs to transfer money across banks to B, then it involves data from two banks, and the ACID of the transfer cannot be guaranteed by a local transaction of one database, and can only be solved by distributed transactions.
A distributed transaction means that the transaction initiator, resource and resource manager and transaction coordinator are located on different nodes of the distributed system. In the above transfer operation, the user A -100 operation and the user B +100 operation are not located on the same node. Essentially, distributed transactions are designed to ensure the correct execution of data operations in a distributed scenario.
Distributed transactions can be divided into two categories.
- The first category is the internal distributed transaction of NewSQL, which is not the focus of our discussion today and will only be briefly described.
- The second category is: cross-database, cross-service distributed transactions, which are the main subject of dtm and will be explained in detail later.
NewSQL distributed transactions
NewSQL, represented by Spanner and TiDB, implements ACID transactions between multiple nodes in the internal cluster, i.e., the transaction interface provided to users is no different from ordinary local transactions, but internally, a transaction supports multiple data writes from multiple nodes, which cannot use the MVCC technology of local ACID, but will use a set of complex distributed MVCC to do ACID. Most of the NewSQL distributed transaction technologies use the core technology introduced in this paper Percolator.
So from a CAP perspective, you can't have all three at the same time, so what does NewSQL choose and what does it sacrifice?
First let's look at C (consistency), which is a must for database type applications. As long as the data is written, the subsequent reads, must get the latest written results. You can imagine if this is not the case, then your application processing critical transactions such as orders, if the results read is not the latest, then you will not be able to determine the current accurate state of the order, it can not be processed correctly.
Then we look at P (partitioning). As long as it is a distributed system, then P is bound to happen with probability, so P is a characteristic that a distributed system must handle and must have.
Then we look at A (availability), due to the development of the architecture, the frequency of network partitioning of the system can be significantly reduced. In addition, the development of distributed consensus algorithms allows to recover from partition failures in a shorter period of time by correctly reaching consensus. Public data from Google's distributed lock Chubby shows that the cluster can provide an average availability of 99.99958%, which is only 130s of down time a year. Such availability is quite high and has minimal impact on real-world applications.
This means that with the development of modern engineering and consensus algorithms, it is possible to construct systems that satisfy CP while coming close to satisfying A. This can be called CP+HA, where HA stands for not 100% A, but rather very high availability.
Public data shows that Google's Spanner supports the transactional feature of ACID while providing a high availability of 5 out of 9, so it is a CP+HA.
Since NewSQL has achieved CP+HA, from the CAP perspective, the typical Dynamo systems such as those introduced earlier in BASE have only achieved AP, so are they out of history? No! The performance difference between NewSQL and BASE systems can be huge, so there are many application scenarios for BASE in actual high performance and high concurrency applications.
Distributed Transactions Across Services and Libraries
Distributed transactions
Although there are two types of distributed transactions, one is the NewSQL distributed transaction introduced earlier, which is not the focus of DTM research, and the other is the cross-service cross-library distributed transaction that DTM focuses on.
In order to simplify the description, this tutorial if no specially stated, key words: distributed transactions refers to the cross-library cross-service update data distributed transactions
dtm focuses on cross-service, cross-database distributed transactions, which are distributed transactions that only partially follow the ACID specification of.
- Atomicity: strict adherence to
- Consistency: consistency after the completion of the transaction is strictly followed; consistency in the transaction is relaxed
- Isolation: no influence between parallel transactions; visibility of results in the middle of the transaction is relaxed
- Persistence: Strictly followed
Consistency and isolation are not strictly adhered to. But in the four characteristics of ACID, the three characteristics AID is actually a database implementation of people very concerned. But for the end user of the database, the C is mostly concerned. In the user perspective, what is the consistency of distributed transactions?
For the C (consistency) here, let's take a very specific business example to explain it. Suppose we are dealing with a transfer of money, let's say A transfers $30 to B. With the support of a local transaction, our user sees that the total amount of A+B remains the same before, during and after the entire transfer. Then this time the user thinks that the data he sees is consistent and conforms to the business constraints.
When our business becomes more complex and we introduce multiple databases and a large number of microservices, the consistency of the above-mentioned local transactions is still of great concern to the business. If a business update operation is performed across databases or services, then the consistency problem of distributed transactions shows up.
In a single local transaction, the total amount of A+B at any moment to check (with the common ReadCommitted or ReadRepeatable isolation level), is unchanged, that is, the business constraints have always maintained this consistency, we call it strong consistency.
Unable to be strongly consistent
In practical distributed applications. We have not yet seen a strong consistency solution.
Let's look at XA transactions, which have the highest level of consistency in distributed transactions (readers can refer to XA transactions). Is it strong consistency? Let's take a cross-bank transfer (here, we simulate it with a cross-database update) as an example to analysis. The following is a timing diagram of an XA transaction.

In this timing diagram, we launch the query at the point of time (in the middle of two commits) shown in the diagram. The result will be A+B+30, which is not equal to A+B. So in this case, XA does not meet the requirement of strong consistency.
The result from microservice 1 is A, because the transaction A-30 is not committed; The result from microservice 2 is B+30; So the sum is A+B+30
In a distributed system, it it impossible to finish two commits at the same time, so that strong consisitency can't be achieved.
Theoretical Strong Consistency
Since ordinary XA transactions are not strongly consistent, then is it theoretically possible to achieve strong consistency if performance not taken into account at all?
Let's first see whether we can achieve strong consistency if we set the isolation level of the database involved in the XA transaction to Serializable. Let's look at the previous timing scenario.

In this case, the result is checked to be equal to A+B.
The result from microservice 1 is A-30, because under Serializable Isolation, the query will wait until the transaction A-30 is committed; The result from microservice 2 is B+30; So thhe sum is A+B.
But then there are other scenarios where problems arise, as shown in the following figure.

The result of the query according to the timing in the figure is: A+B-30, which is inconsistent.
The result from microservice 1 is A-30, because under Serializable Isolation, the query will wait until the transaction A-30 is committed; The result from microservice 2 is B, because the transaction B+30 has not yet started; the sum is A+B-30.
After thinking deeply about this issue of strong consistency, there is a way to achieve strong consistency under a normal read-commit, as follows.
- For queries, also use XA transactions, and when querying data, use select for update, and then xa commit after all data has been read
- In the current timing diagram, we need to lock A to check A, then lock B to check B, and then commit separately, otherwise deadlocks may occur
With the above strategy, we can see that querying at any point in the timing diagram, the result obtained is A+B

- query at time T0, then the modification must have happened after the query is all done, so the query gets the result A+B
- In T1, T2, T3 query, the query results will only be returned after the completion of all the changes, and results are also A + B
It is clear that the disadvantages of strong consistency in this scenario are numerous. Whereas most Internet applications are read more and write less, the normal read can be done quickly without being locked by MVCC. But the strongly consistent scheme described above:
- On the one hand, the efficiency is extremely low, all operations of database which have data intersection must be executed serially.
- On the other hand, deadlocks can occur when developers make multiple data queries to the database, either allowing developers to carefully shoot for a good access sequence or accept the deadlock.
There are currently no real-world applications that have adopted this approach for strongly consistent cross-database distributed transactions.
Is it possible to use the approach from NewSQL to achieve strong consistency of such distributed transactions across libraries and microservices? Theoretically, it is possible.
- A relatively simple approach to achieve distributed transaction consistency across services but not across databases, is to implement the TMRESUME option in XA transactions. The inconsistency of XA transactions comes from the fact that two commits on a distributed system cannot be completed at the same time. Now that it is already in a database, just across services, then TMRESUME allows us to move the xa transaction of a certain service onward. When it is finally committed, there is only one xa commit, thus avoiding inconsistent time window between 2 xa commits and achiving strongly consistent.
- Achieving distributed transaction consistency across databases is much more difficult because the internal versioning mechanisms of each database are different and it is very difficult to collaborate. The difficulty comes from two points: First, the MVCC mechanism is different among different vendors, for example, Spanner is TrueTime, TiDB is single-point timing, and some are logical clocks, so it is very difficult to be compatible with multiple MVCCs. Second, it is difficult for different vendors to have enough business interests to drive such synergy.
Eventual Consistency
As we can see from the previous analysis, consistency cannot be guaranteed while the distributed transaction is in progress. But after the distributed transaction is completed, consistency is no problem and strictly adhered to. Therefore, we call the distributed transaction scheme the eventual consistency scheme. This eventual consistency is the same word as the eventual consistency in CAP, but their specific meanings are different. In CAP, it means that the read operation can eventually read the result of the last write. But in distributed transaction, it means that the data strictly satisfies the business constraints after the completion of the distributed transaction.
Since all existing distributed transaction mode are not able to achieve strong consistency, is there a difference between eventual consistency? We have performed the following classification on the strength of consistency.
The consistency from strong to weak are.
XA transactions>TCC>two-phase message>SAGA
They are classified as. 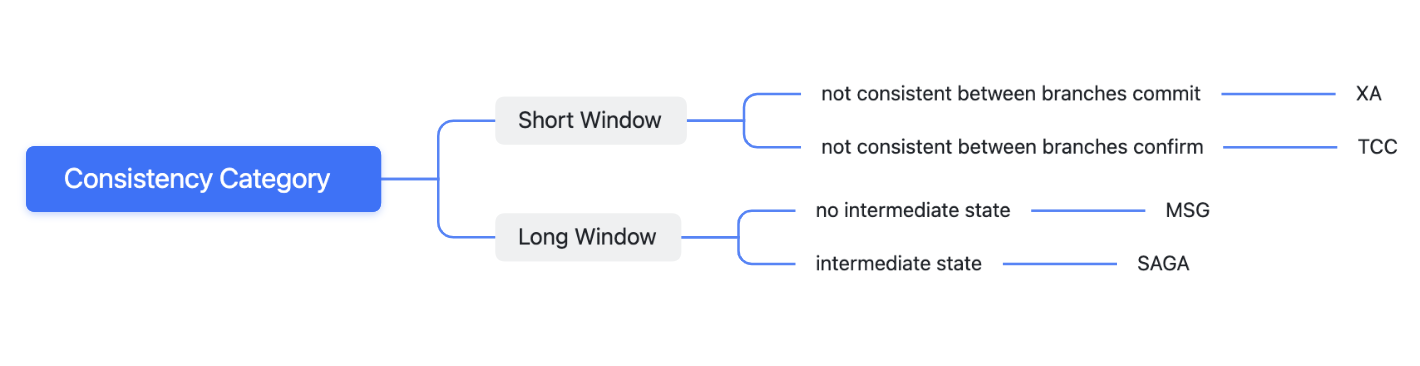
- Short inconsistency window: XA and TCC can achieve a short inconsistency window under ideal circumstances
- Long inconsistency window: SAGA and MSG, on the other hand, lack a way to control the inconsistency window time and will be relatively longer
- XA: XA is not strongly consistent, but the consistency of XA is the most consistent, because the inconsistent state of time is very short. The inconsistent time window is between the moment first branch committed and the moment all branches committed. Because the commit operation of the database usually finished within 10ms, the window of inconsistency is short.
- TCC: In theory, TCC can be implemented with XA, such as Try-Prepare, Confirm-Commit, Cancel-Rollback, but most of the time, TCC will implement Try|Confirm|Cancel in the business layer itself, so the Confirm operation usually take more time than the XA commit, and the inconsistent window time is longer than XA
- MSG: 2-phase message transactions are inconsistent after the first operation completes and before all operations are completed. So the inconsistent window is usually longer than the XA and TCC.
- SAGA: The inconsistency window duration of SAGA is close to that of messages, but rollback may occur in Saga. If transaction branch update data A to A1, then A1 is read by user, then A1 is rollbacked to A. In this case, A1 read by user is a wrong data, which tends to give the user a poorer experience. Thus saga consistency is the worst.
Our classification here summarizes just a few dimensions we care about, and is applicable to most scenarios, but not necessarily to all cases.
Summary
Here, we have introduced the theory related to distributed transactions and analyzed the eventual consistency of distributed transactions. Next, we will introduce the architecture and practice of DTM